
推荐模型性能定律:量化分析模型规模、数据规模和质量对推荐系统性能的影响
中国科学技术大学认知智能全国重点实验室陈恩红团队与华为诺亚方舟实验室合作,提出了一种推荐模型性能定律,首次对模型性能与模型规模、数据规模及质量进行了定量分析。该研究突破...
推荐模型性能定律:量化分析模型规模、数据规模和质量对推荐系统性能的影响
中国科学技术大学认知智能全国重点实验室陈恩红团队与华为诺亚方舟实验室合作,提出了一种推荐模型性能定律,首次对模型性能与模型规模、数据规模及质量进行了定量分析。该研究突破了现有工作仅能对推荐大模型扩展定律进行定性分析的局限性,实现了对推荐大模型性能扩展定律的定量预测。
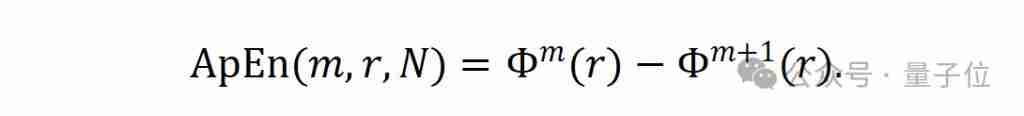
这项研究的关键在于,它针对推荐领域的数据特性,提出了序列数据的质量衡量指标,并从模型性能预测角度出发,有效避免了传统扩展定律中参数增大导致的模型过拟合问题。基于该定律,研究人员能够在给定的数据集和模型配置下,有效预测模型的扩展潜力,并确定模型参数的最优性能配置。
挑战与创新:
传统的大模型扩展定律主要关注模型损失指标,但在推荐系统中,命中率等性能指标更为关键。此外,推荐系统数据具有结构和协作特性,且存在重复序列片段和冗余度,数据质量成为影响性能的关键因素。该研究正是针对这些挑战,提出了创新性的解决方案。
核心改进:
- 新的数据质量指标: 研究人员引入近似熵 (ApEn) 作为衡量数据质量的指标,并使用 ApEn′ = 1/ApEn 作为最终测度。近似熵值越高,数据的重复率越高,该指标有效避免了数据冗余导致的数据量虚高问题。 研究还证明了最小编码长度作为数据质量衡量指标的下界。
- 改进的扩展定律公式: 将原有扩展定律中的数据规模替换为数据规模与近似熵之比,并通过理论和实验验证了这一替代的合理性。最终的模型拟合公式包含了模型层数、嵌入维度和改进后的数据质量指标。
- 有效预测模型性能: 通过拟合命中率 (HR) 和归一化折扣累积增益 (NDCG) 等关键性能指标,定量预测模型的层数和物品嵌入维度对其性能的影响。

实验验证:
研究人员进行了验证实验,结果表明:
- 模型损失曲线与扩展法则高度一致。
- 数据参数与 ApEn 的组合呈现出明确的线性关系,验证了理论的有效性。
- 基于该定律,可以有效预测模型的最优性能参数配置和扩展潜力。
论文链接:https://www.php.cn/link/fcb54c1f6bae8c57b82ec40610f72ee6
这项研究为推荐系统模型的开发和优化提供了重要的理论指导和实践方法,有助于更有效地利用资源,提升推荐系统的性能。
以上就是推荐场景 Scaling Law 来了!中科大 & 华为诺亚方舟联合推出的详细内容,更多请关注知识资源分享宝库其它相关文章!
版权声明
本站内容来源于互联网搬运,
仅限用于小范围内传播学习,请在下载后24小时内删除,
如果有侵权内容、不妥之处,请第一时间联系我们删除。敬请谅解!
E-mail:dpw1001@163.com











发表评论